Inside magicplan
In part 2, we showed how you could reach a good level detection accuracy on a Deep Learning model running on powerful GPU, when you have the right expertise on Deep Learning training. Unfortunately, this is not enough when you want to implement the feature on a smartphone and have to deal with really limited hardware resources both in terms of memory and computing power.
Embedding the feature into a smartphone
At first, the contemplated solution was to offload the GPU computation on the cloud.
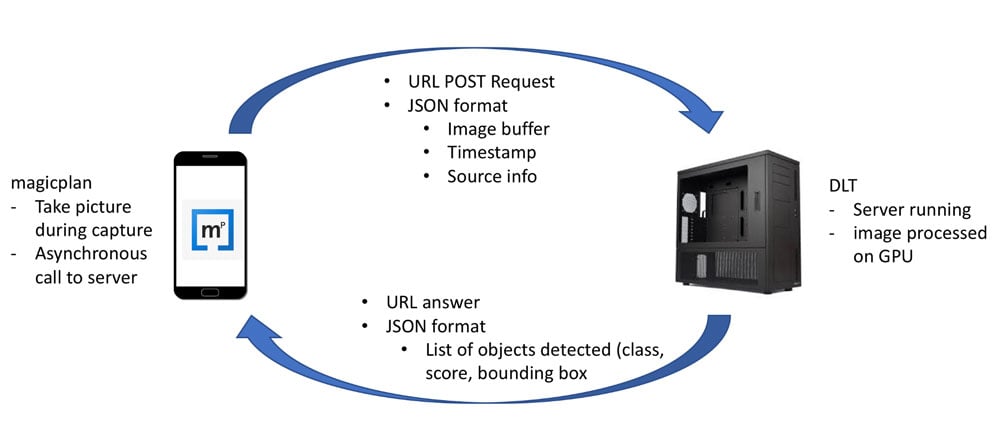 Remote GPU based solution
Remote GPU based solution
We have to thank the MILA laboratory with whom we collaborated in an IRAP funded initiative as they recommended us this approach as a way of shrinking the model and it worked! It was key to have MILA expertise guiding us on this solution, a solution we would have most likely not considered otherwise.
This advanced approach is quite fascinating. To make it short, it relies on the idea that small models are worse at generalising than large models during the training procedure. So, in order to have good training for a small model, it helps to have a large model “distilling” knowledge from its internal layers into some internal layers of the small model.
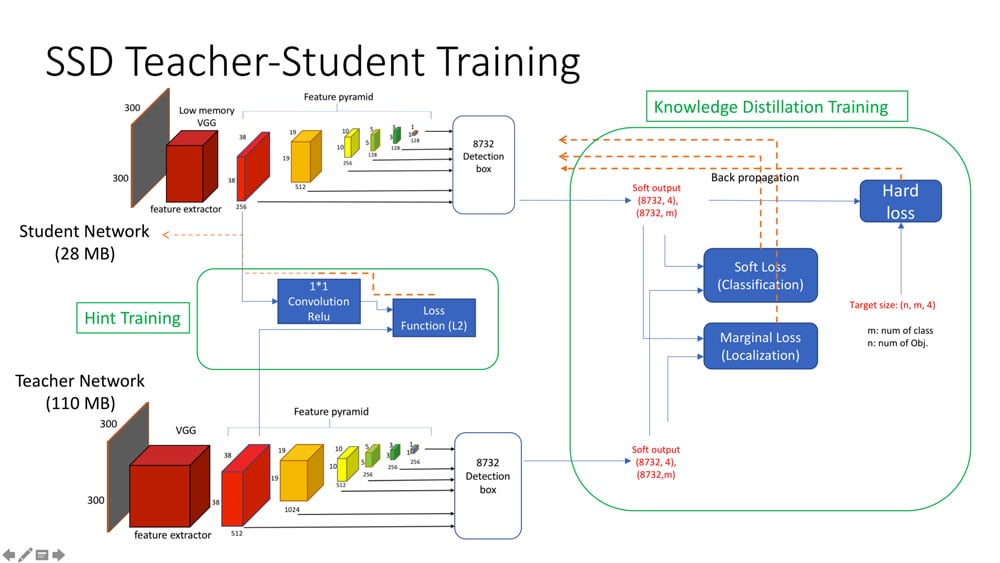
Teacher — Student implementation
More on the topic:

Pierre Pontevia
Limited offer
New to magicplan? Schedule a demo with our sales team to get a free introduction.

Share article