Inside magicplan
In part 1, we saw how today’s Deep Learning tools and data ecosystems make it easy to have an early prototype to assess the feasibility of a common Deep Learning task. That said, it is one thing to have a workable prototype showing the potential of the approach, it is another thing to reach a reliable enough level of detection to allow the feature to be put in the hands of millions of users.
Iterating on data and model to reach acceptable performance
As shown in this video, the objective of magicplan-AI is to let the user add a door or a window on a given wall, both at the correct position and with the correct size by simply taking a picture of the object while capturing the room.
This capture needs to be reliable in terms of location and size and real-time to avoid downgrading the quality of the already in-production room capture.
By reliable, we mean several things:
- ability to detect the existence of a door or a window on a picture,
- ability to classify correctly as window or door the detected object,
- ability to provide an accurate bounding box for the detected object.
Introducing relevant performance metrics
To measure the performance of such a system, we use a metrics called F1 , that “summarises” in one single value the combination of most of above requirements (important factors such as true positive, false positive and false negative).
Note: there are other metrics like the mAP (mean Average Precision) that are more complete, but for the sake of simplicity, I will stick to F1 in this story. It is important to understand that, depending on the usage scenario for a given object detector, errors of different nature can have very dissimilar impact.
A powerful illustration of this is a cancer cell detector, for which the impact of not detecting a real cancerous cell has catastrophic consequences compared to the impact of wrongly classifying a sane one.
The same asymmetry exists in magicplan capture scenario:
- wrongly classifying a correctly detected and framed window as a door is easy to correct by the user with the proper UI (one click operation),
- on the opposite, poorly adjusting bounding box of a correctly detected and classified window will oblige the user to switch to edition mode and input the correct measurement obtained by alternate means (very time consuming and disruptive).
This asymmetry in the cost of object detection errors needs to be reflected in the used metrics by handling specifically each error type. Once the metrics are defined, we can rely on a quantitative approach to evaluate the different iterations of our object detector:
- our POC “SSD Inception V2” model trained with ImageNet database had a F1 score of 0.62,
- qualitatively, the POC model was failing to detect some types of doors and lacked accuracy in the bounding box.
Three methods have been used to improve the F1 score:
- improving / augmenting the training dataset, playing with
- the loss function,
- exploring different architectures.
Improving / augmenting the training dataset
In the world of Deep Learning, data is key and there are a lot of identified techniques to improve the training database. The first one is obviously to increase the size of the training dataset by adding more images or data augmentation techniques. But surprisingly, for us, the most significant improvement came from cleaning the annotated ImageNet database.
There are several reasons to that:
1. not all images with doors or windows are relevant to magicplan interiors scenario use cases — we call this a domain shift issue,

Not the type of door we are interested in!
2. door and windows are generic words that you can find in situations that have nothing to do with a house interior — we call this a semantic shift issue,

A plane window is not a house window!
3. crowd-sourcing annotation has its limits and mistakes can be included in the annotation — we call this a mis-annotation issue,

Wrong annotation!
4. while it is ok to annotate only one window in a picture containing several windows for a classification task, it is not ok to forget to annotate visible windows for an object detection task — we would call this a partial-annotation issue,

Somebody forgot to annotate the windows!
5. we realized that doors when shot open can be problematic for magicplan-AI as we actually are looking for the door frame, not the mobile part — we call this a task annotation shift issue.

Not the part of the door we want to detect!
For each type of issue, a fix was identified and applied.
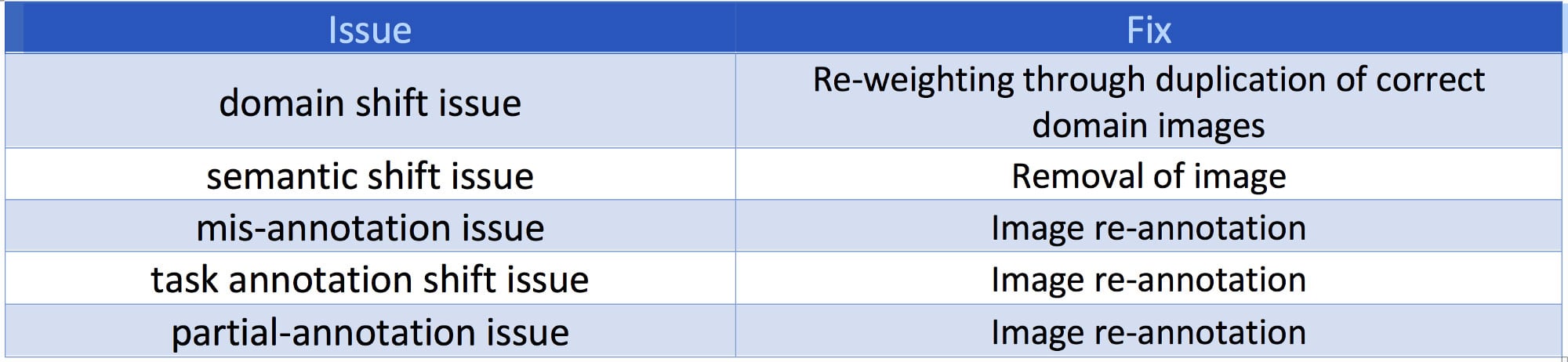
Training set issues and fixes
Revisiting the training dataset and removing, re-annotating or re-weighting images, improved F1 score by more than 23%, reaching an interesting 0.85.
Playing with the loss function
Training correctly a model in Deep Learning is as much about the right dataset as it is about the right correction when an error is found during the training.
Fortunately for us, a large literature is available on identifying the right Loss function to use. Even better, on the particular case of Object detection, Facebook Detectron project identified some key improvement in the way of applying the right Loss function, called Focus Loss, that were very easy to implement for us.
As a result, combining the training database quality improvement with the introduction of a better fitted loss function, we were able to significantly improve the F1 score as illustrated below.
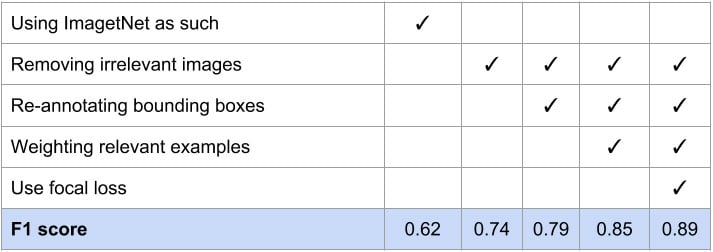
F1 score evolution according to Training set fixes
Exploring different architectures
Academic research has been quite active in the Object Detection field and several architectures are available for Deep Learning for Object Detection. They can be grouped along two axes:
A — the type of feature extractor that processes the input image:
- Multiple architectures from lite (MobileNet) to heavy (Inception, VGG, ResNet)…
- the bigger the feature extractor in terms of parameters, the better the descriptors but the more memory and time it takes to perform
B — the number of steps to do the full detection:
- direct forward approach (YOLO, SSD) where one single network will detect the bounding boxes and classify them at the same time,
- two steps approach (Faster RCNN, R-FCN) where a first network detects potential rough bounding boxes candidates while the second performs classification and bounding boxes fine tuning.
As expected, the more complex the architecture, the better the performance (see graphic below).
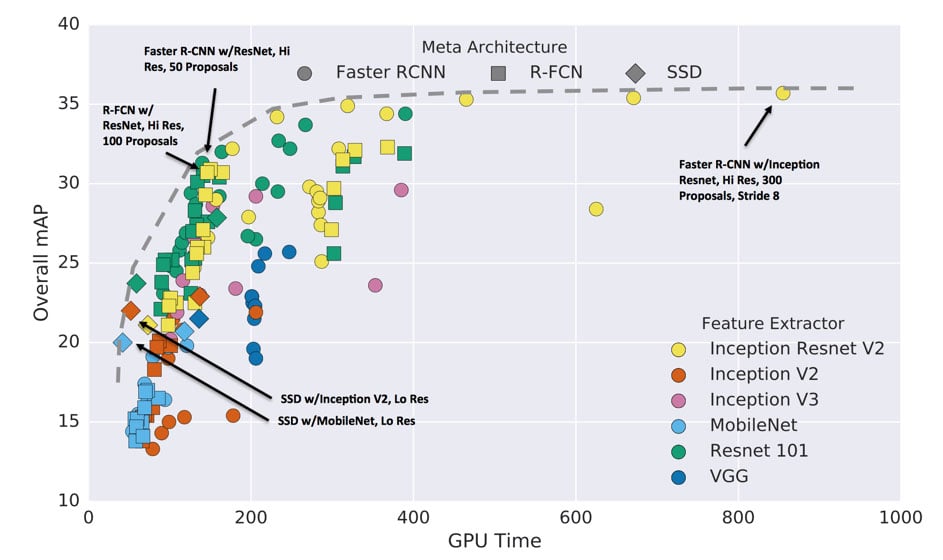
Object Detection Architectures and performances (COCO dataset) — Source
However, what we discovered quite early is that even for the inference task (the task of running the model to perform the object detection on an image — not the training task which requires much more resources), not all architectures fit the constraints of running on a mobile device.
Two reasons to that:
- contrary to modern GPU boards with more than 10Gb of RAM, even the latest iPhone X has only 3Gb of RAM,
- real-time constraint means that we can’t afford an object recognition lasting more than 1.0 second without creating a really annoying lag in the user experience.
Some architectures do not fit in memory on the device. Some other do BUT it takes several seconds to process one object detection, which is not acceptable in the magicplan real-time capture scenario.
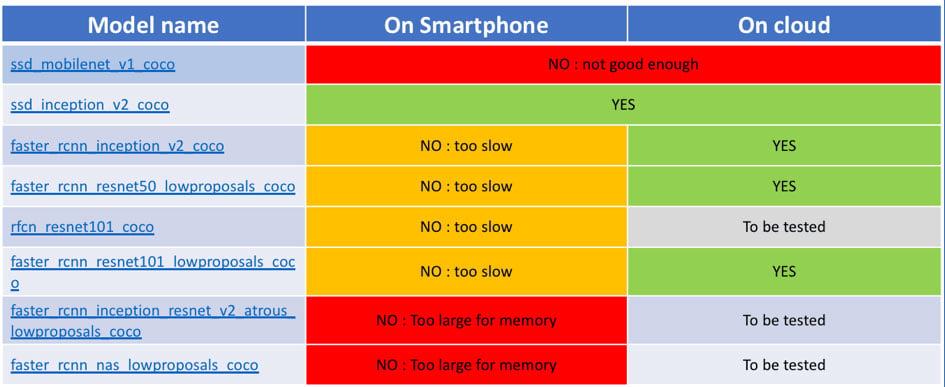
Evaluation of several architectures
Lessons learnt
Contrary to the first “quick & easy” stage, being able to play with all the options in the “off the shelf” models requires several conditions:
- a good methodology to objectively measure the progress,
- a good understanding of what makes a good training convergence and what can break it,
- a good understanding of the underlying neural nets architecture and nodes,
In our case, this could not have happened without the presence of two full time PhDs in artificial intelligence / deep learning in the team who master these challenges.
Coming next
At this point we have a best in class model doing a good job in object detection but too big to run on any modern smartphone. In last part, we will describe more in detail the work required to move from a PC based solution to a smartphone embedded one.

Pierre Pontevia
Limited offer
New to magicplan? Schedule a demo with our sales team to get a free introduction.

Share article